
Bu uygulamamızda yine www.kaggle.com‘dan indirdiğimiz ve aşağıda açıklaması verilen veri setini kullanacağız. Veri Setini buradan indirebilirsiniz.
Bu veri seti, bir tıp araştırması için toplanan verileri içeriyor. Araştırmacılar, aynı hastalığa sahip bir grup hastadan veri toplamıştır. Tedavi süreci boyunca, her hasta beş farklı ilaçtan birine yanıt vermiştir: İlaç A, İlaç B, İlaç C, İlaç X ve İlaç Y.
Bu veri setiyle amaç, aynı hastalığa sahip gelecekteki bir hastaya hangi ilacın uygun olabileceğini belirlemek için bir model oluşturmaktır. Veri setinin özellikleri hastaların yaşları, cinsiyetleri, kan basınçları ve kolesterol düzeyleridir. Hedef değişken, her hastanın yanıt verdiği ilaçtır.
Bu veri seti, çok sınıflı bir sınıflandırma probleminin örneğidir. Veri setinin eğitim bölümünü kullanarak bir karar ağacı oluşturabilir ve daha sonra bilinmeyen bir hastanın sınıfını tahmin etmek veya yeni bir hastaya bir ilaç reçete etmek için kullanabilirsiniz.
Veri setinin kolonları hakkında daha detaylı bilgi verelim:
- Yaş (Age): Hastaların yaşlarını temsil eder. Sayısal bir değerdir.
- Cinsiyet (Sex): Hastaların cinsiyetini temsil eder. Kategorik bir değişkendir ve genellikle “M” (erkek) veya “F” (kadın) olarak kodlanır.
- Kan Basıncı (Blood Pressure): Hastaların kan basıncını temsil eder. Kategorik olarak “DÜŞÜK”, “NORMAL” ve “YÜKSEK” gibi gruplara ayrılmıştır.
- Kolesterol (Cholesterol): Hastaların kolesterol seviyelerini temsil eder. Kategorik olarak “DÜŞÜK”, “NORMAL” ve “YÜKSEK” gibi gruplara ayrılmıştır.
- Na/K Oranı (Na_to_K): Hastaların sodyum (Na) ve potasyum (K) oranını temsil eder. Bu sayısal bir değerdir.
- İlaç (Drug): Hastaların yanıt verdiği ilacı temsil eder. Bu, modelimizin tahmin etmeye çalışacağı hedef değişkendir ve genellikle “İlaç A”, “İlaç B”, “İlaç C”, “İlaç X” ve “İlaç Y” gibi kategorik değerler alır.
Bu kolonlar, veri setindeki her bir özelliği temsil eder. Bu bilgiler, modelimizi oluştururken ve sonuçları yorumlarken bize rehberlik eder.
Uygulama
Şimdi adım adım karar ağacı uygulamamızı yapalım.
1. Gerekli Kütüphanelerin İçe Aktarılması, Veri Setinin Yüklenmesi ve İncelemesi: İlk olarak, gerekli kütüphaneleri içe aktaralım, veri setini yükleyelim ve içeriğini inceleyelim. Bu adım, veri setinin yapısını ve içeriğini anlamamıza yardımcı olur.
import pandas as pd # Veri işleme ve manipülasyonu için
import numpy as np # Sayısal işlemler için
import matplotlib.pyplot as plt # Görselleştirme için
import seaborn as sns # Veri görselleştirmesi için
from sklearn.model_selection import train_test_split # Veriyi eğitim ve test setlerine ayırmak için
from sklearn.tree import DecisionTreeClassifier, plot_tree # Karar ağacı modeli oluşturmak için
from sklearn.metrics import accuracy_score, confusion_matrix # Model performansını değerlendirmek için
from sklearn.preprocessing import LabelEncoder # Kategorik değişkenleri sayısallaştırmak için
# Veri setini yükleme
data = pd.read_csv("data.csv")
# Veri setinin ilk beş gözlemine bakma
print(data.head())
Çıktı:
Age Sex BP Cholesterol Na_to_K Drug
0 23 F HIGH HIGH 25.355 drugY
1 47 M LOW HIGH 13.093 drugC
2 47 M LOW HIGH 10.114 drugC
3 28 F NORMAL HIGH 7.798 drugX
4 61 F LOW HIGH 18.043 drugYBu adımda, head() fonksiyonunu kullanarak ilk beş gözlemi görüntüleriz, böylece veri yapısını görsel olarak anlayabiliriz.
2. Kolon Başlıklarının Türkçeleştirilmesi ve Kategorik Değişkenlerin Sayısallaştırılması: Veri setinin kolon başlıklarını anlaşılır bir şekilde Türkçe’ye çevirerek başlayalım. Ardından, modelimizin kullanabileceği sayısal değerlere dönüştürmemiz gereken kategorik değişkenleri sayısallaştıracağız.
# Kolon başlıklarını Türkçeleştirme
data.columns = ["Yaş", "Cinsiyet", "Kan_Basıncı", "Kolesterol", "Na_K_oranı", "İlaç"]
# Cinsiyet kolonunu sayısallaştırma
le = LabelEncoder()
data["Cinsiyet"] = le.fit_transform(data["Cinsiyet"])
# Kan_Basıncı ve Kolesterol kolonlarını sayısallaştırma
data["Kan_Basıncı"] = le.fit_transform(data["Kan_Basıncı"])
data["Kolesterol"] = le.fit_transform(data["Kolesterol"])
Çıktı:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 200 entries, 0 to 199
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Yaş 200 non-null int64
1 Cinsiyet 200 non-null int64
2 Kan_Basıncı 200 non-null int64
3 Kolesterol 200 non-null int64
4 Na_K_oranı 200 non-null float64
5 İlaç 200 non-null object
dtypes: float64(1), int64(4), object(1)
memory usage: 9.5+ KB
NoneBu adımda, veri setindeki kolon başlıklarını Türkçe’ye çevirerek veriyi daha anlaşılır hale getiriyoruz. Daha sonra, kategorik değişkenleri (Cinsiyet, Kan_Basıncı ve Kolesterol) sayısal değerlere dönüştürmemiz gerekiyor çünkü makine öğrenimi modelleri doğrudan kategorik değerlerle çalışamazlar.
3. Korelasyon Haritasının Oluşturulması: Değişkenler arasındaki ilişkiyi daha iyi anlamak için bir korelasyon haritası oluşturalım.
from sklearn.preprocessing import LabelEncoder
# LabelEncoder oluşturma
le = LabelEncoder()
# İlaç sütununu sayısallaştırma
data["İlaç"] = le.fit_transform(data["İlaç"])
# Korelasyon matrisini hesaplama
correlation_matrix = data.corr()
# Korelasyon matrisini görselleştirme
plt.figure(figsize=(10, 8))
sns.heatmap(correlation_matrix, annot=True, cmap="coolwarm", fmt=".2f", linewidths=0.5)
plt.title("Değişkenler Arası Korelasyon Haritası")
plt.show()
Çıktı:
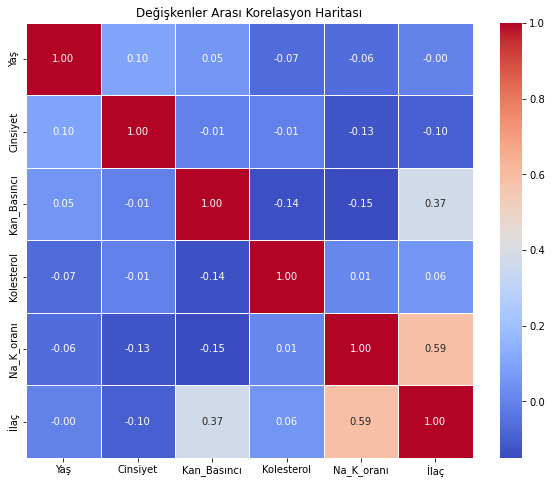
Korelasyon haritası, değişkenler arasındaki ilişkileri görsel olarak temsil eder. Bu, değişkenlerin birbiriyle nasıl ilişkili olduğunu ve modelin performansını etkileyebilecek potansiyel bağlantıları görmemizi sağlar.
4. İkili Değişken Grafiklerinin Oluşturulması: Değişkenler arasındaki ilişkiyi daha iyi anlamak için ikili değişken grafiklerini çizelim.
# İkili değişken grafiklerini çizme
sns.pairplot(data)
plt.show()
Çıktı:
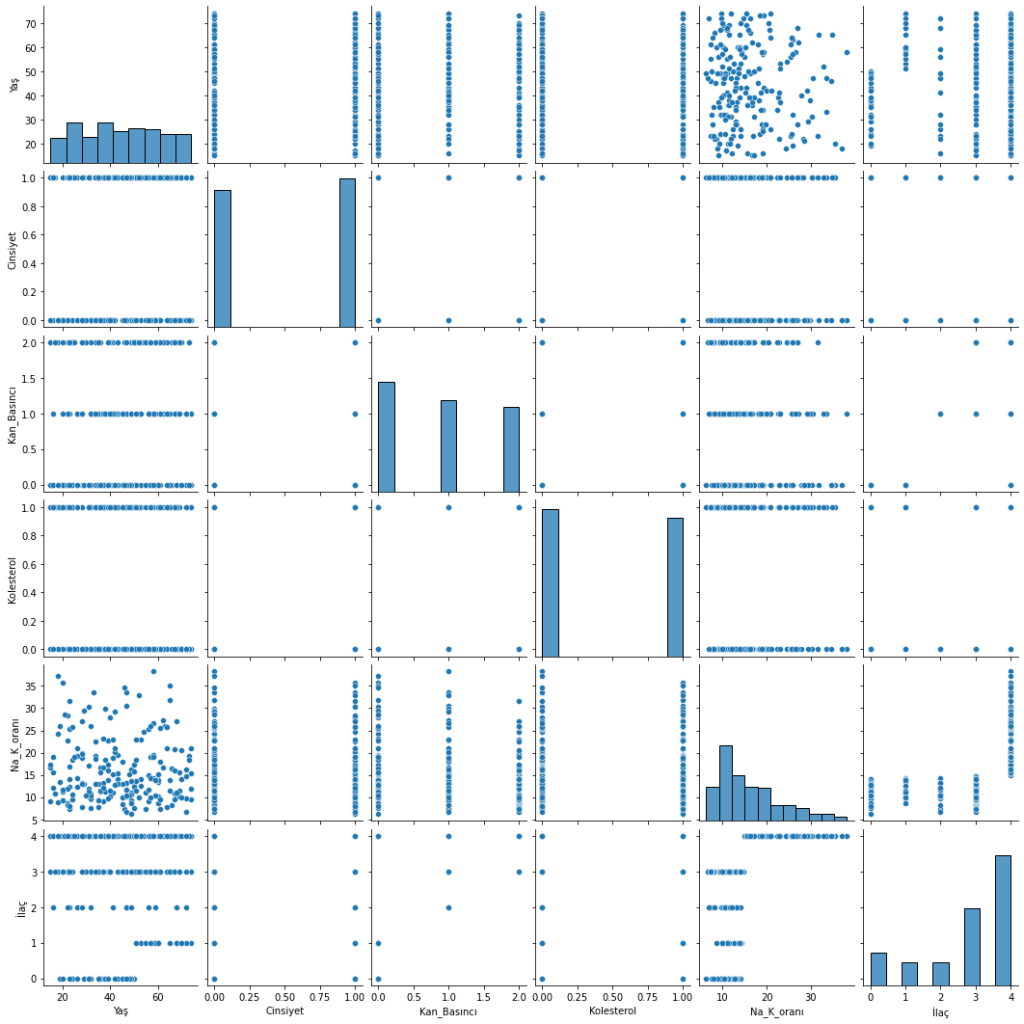
Bu grafikler, her iki değişken arasındaki ilişkiyi dağılım grafiği şeklinde gösterir. Bu, değişkenlerin birbirleriyle nasıl ilişkili olduğunu ve veri setinin dağılımını daha iyi anlamamıza yardımcı olur.
Bu adımları takip ederek, modelimizi oluşturmak ve veriyi daha iyi anlamak için gerekli görselleştirmeleri oluştururuz. Sonraki adımda, modelimizin performansını değerlendirmek için test seti üzerinde tahminler yapacağız.
5. Eğitim ve Test Setlerinin Oluşturulması: Modeli eğitmek ve test etmek için veri setini eğitim ve test setlerine böleceğiz. Bu, modelin gerçek dünya verileri üzerinde ne kadar iyi performans gösterebileceğini anlamamıza yardımcı olur.
# Bağımsız değişkenler ve hedef değişken arasında ayırma
X = data.drop("İlaç", axis=1)
y = data["İlaç"]
# Eğitim ve test setlerine ayırma
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Bu adımda, modelimizi eğitmek ve test etmek için veri setini ikiye böleriz. Veri setinin %80’ini eğitim için kullanırken, %20’sini test için kullanıyoruz. Ayrıca, random_state parametresi ile rastgelelik kontrol edilir, böylece her çalıştırmada aynı sonuçları elde ederiz.
Bu adımları takip ederek, veri setini yükler, işler ve modelin eğitim ve test sürecine hazırlarız. Bir sonraki adımda modelimizi oluşturarak devam edelim.
6. Karar Ağacı Modelinin Oluşturulması ve Görselleştirilmesi: Karar ağacı, veri setindeki desenleri bulmak için sınıflandırma ve regresyon problemlerinde kullanılan bir makine öğrenimi algoritmasıdır. Modelimizi eğitmek için eğitim seti üzerinde bir karar ağacı modeli oluşturalım.
# Karar ağacı modelini oluşturma
clf = DecisionTreeClassifier(random_state=42)
clf.fit(X_train, y_train)
# Karar ağacını görselleştirme
plt.figure(figsize=(15, 10))
#plot_tree(clf, feature_names=X.columns, class_names=clf.classes_, filled=True)
plot_tree(clf, feature_names=X.columns, class_names=[str(c) for c in clf.classes_], filled=True)
plt.show()
Çıktı:
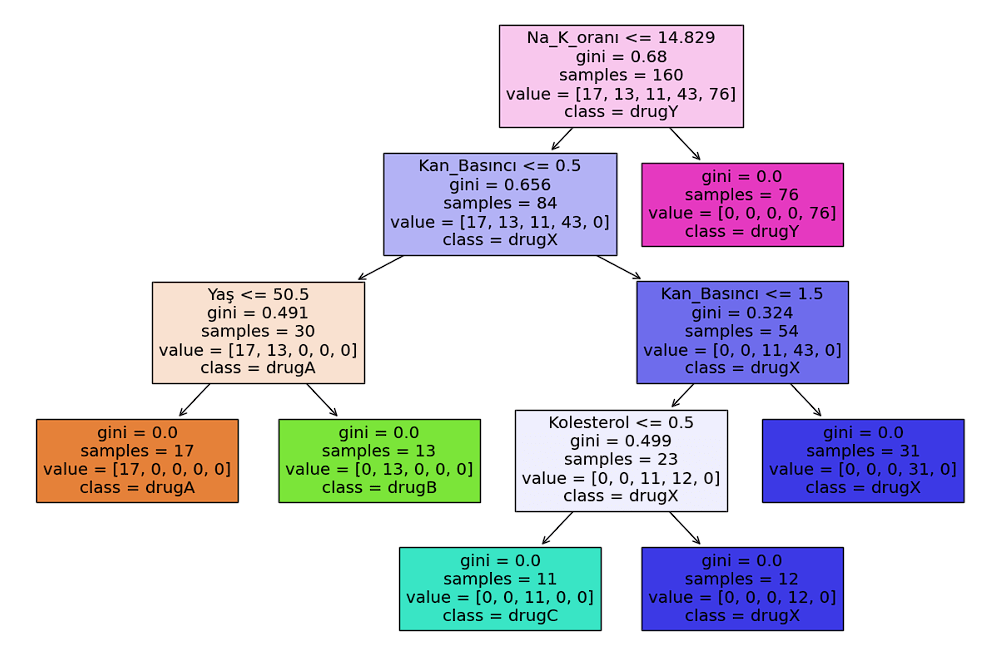
Karar ağacı, veri setindeki özelliklerin değerlerine göre kararlar alır ve bu kararlar ağacın dallarında temsil edilir. Bu görselleştirmede, her bir düğümdeki koşullar ve dallar arasındaki ilişkiler açıkça görülebilir.
7. Model Performansının Değerlendirilmesi: Modelimizin ne kadar iyi performans gösterdiğini değerlendirmek için doğruluk skoru ve karmaşıklık matrisi kullanacağız.
# Test seti üzerinde tahmin yapma
y_pred = clf.predict(X_test)
# Doğruluk skorunu hesaplama
accuracy = accuracy_score(y_test, y_pred)
print("Doğruluk Skoru:", accuracy)
# Karmaşıklık matrisini oluşturma
cm = confusion_matrix(y_test, y_pred)
print("Karmaşıklık Matrisi:\n", cm)
Sonuç:
Doğruluk Skoru: 1.0
Karmaşıklık Matrisi:
[[ 6 0 0 0 0]
[ 0 3 0 0 0]
[ 0 0 5 0 0]
[ 0 0 0 11 0]
[ 0 0 0 0 15]]Doğruluk skoru, modelin test seti üzerindeki tahminlerinin ne kadarının doğru olduğunu ölçer. Karmaşıklık matrisi, modelin her bir sınıf için doğru ve yanlış sınıflandırmalarını görsel olarak gösterir.
Bu adımları takip ederek, modelimizin performansını objektif bir şekilde değerlendiririz. Bu bize modelin gerçek dünya verileri üzerinde nasıl performans gösterdiği hakkında önemli bir fikir verir. Bu aşamada, modelimizi geliştirmek veya daha fazla inceleme yapmak için geri dönüşler yapabiliriz.
Uygulamayı tüm dosyalarıyla indirmek için tıklayınız.
